经典backbone
AlexNet
创新
- 首次使用GPU训练网络
- 使用Relu激活函数
- 使用LRN局部响应归一化
- 在全连接层加入Dropout
LRN的主要思想是在神经元输出的局部范围内进行归一化操作,使得激活值较大的神经元对后续神经元的影响降低,从而减少梯度消失和梯度爆炸的问题。
为什么说归一化的目的可以被理解为“抑制”?
虽然归一化的主要目的是调整数据的范围和分布,但可以从某种角度将其与“抑制”联系起来:
- 抑制异常值的影响:在归一化过程中,极端值(异常值)会被调整到与其他值相近的范围内,从而减少其对模型训练的负面影响。这种调整可以被看作是对异常值的“抑制”。
- 抑制某些特征的主导作用:如果某些特征的值域远大于其他特征,它们可能会在模型训练中占据主导地位。归一化通过将所有特征调整到相同的范围,抑制了这些特征的过度影响,使模型能够更公平地处理所有特征。
- 抑制过大的梯度:在神经网络中,归一化可以防止某些神经元的激活值过大,从而避免梯度爆炸问题。这种对激活值的调整也可以被看作是一种“抑制”。
Dropout为什么能够解决过拟合:
(1)减少过拟合:
在标准的神经网络中,网络可能会过度依赖于一些特定的神经元,导致对训练数据的过拟合。Dropout通过随机丢弃神经元,迫使网络学习对于任何单个神经元的变化都要更加鲁棒的特征表示,从而减少了对训练数据的过度拟合。(2)取平均的作用:
在训练过程中,通过丢弃随机的神经元,每次前向传播都相当于在训练不同的子网络。在测试阶段,不再进行Dropout,但是通过保留所有的权重,网络结构变得更加完整。因此,可以看作是在多个不同的子网络中进行了训练,最终的预测结果相当于对这些子网络的输出取平均。这种“综合取平均”的策略有助于减轻过拟合,因为一些互为反向的拟合会相互抵消。
VggNet
VGGNet的特点是在训练过程中采用小的卷积核和池化层,并通过堆叠多个卷积层来增加网络的深度,从而实现高精度的图像识别。
VGGNet的亮点在于它通过堆叠多个卷积层,以小的卷积核和池化层的方式来增加网络深度,从而实现高精度的图像识别。这种方法可以有效地捕获图像中的高级特征,并通过不断拟合训练数据来提高识别准确率。
感受野
感受野(Receptive Field),指的是神经网络中神经元“看到的”输入区域,在卷积神经网络中,feature map上某个元素的计算受输入图像上某个区域的影响,这个区域即该元素的感受野。
卷积神经网络中,越深层的神经元看到的输入区域越大,如下图所示,卷积核kernel size 均为3×3,stride均为1,绿色标记的是Layer2绿色神经元看到的区域,黄色标记的是Layer3 看到的区域,具体地,Layer2每个神经元可看到Layer1上3×3 大小的区域,Layer3 每个神经元看到Layer2 上3×3 大小的区域,该区域可以又看到Layer1上5×5 大小的区域。
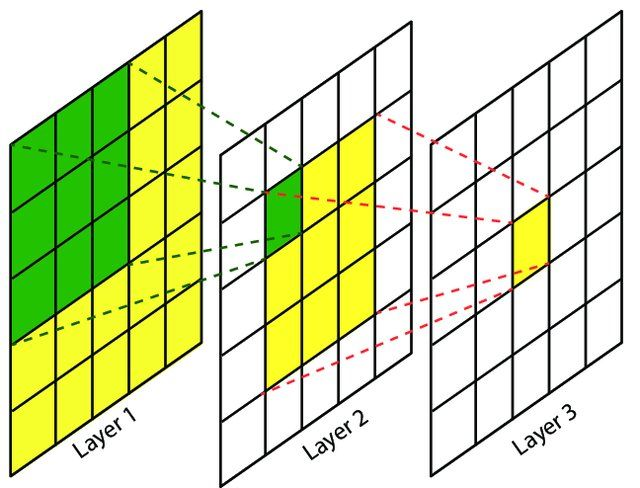
感受野是个相对概念,某层feature map上的元素看到前面不同层上的区域范围是不同的,通常在不特殊指定的情况下,感受野指的是看到输入图像上的区域。
堆叠两个3x3的卷积核可以替代5x5的卷积核,堆叠三个3x3的卷积核可以替代7x7的卷积核,那么通过多个小的感受野的堆叠,替代大的感受野是为了减少网络训练时参数的数量,堆叠三个3x3的卷积核的计算量要小于7x7的卷积核,而且这个差距会随着特征矩阵的channels的变大而扩大
尽管VggNet在许多方面都表现优秀,但它也有一些缺陷:
该网络架构非常大,并且需要大量的计算资源来训练。这意味着,如果你想在较小的设备上使用VggNet,比如移动设备或个人电脑,会发现它非常慢,并且可能无法获得足够的性能。
由于VggNet网络架构非常深,它可能会导致梯度消失或爆炸的问题。这是由于在非常深的神经网络中,梯度在传播过程中可能会变得非常小或非常大,从而导致模型无法正常训练。
GoogLeNet
创新
- Inception结构
- 1*1卷积核降维
- 辅助分类器
Inception结构
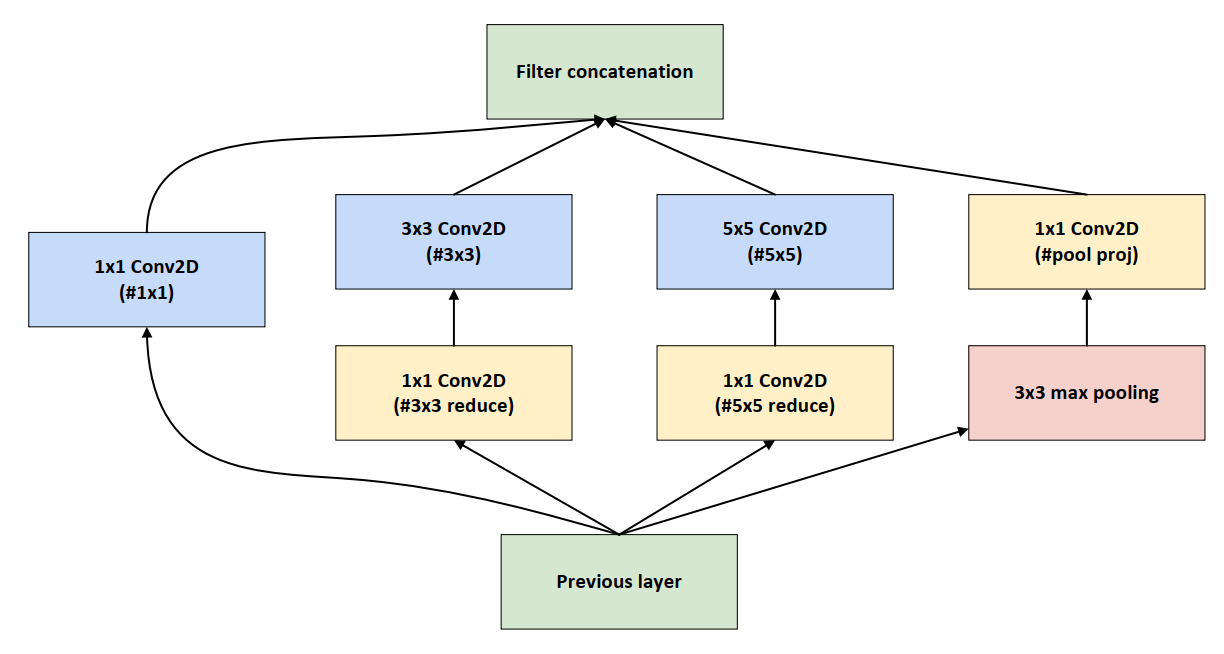
Inception结构是对输入图像并行地执行多个卷积运算或池化操作,并将所有输出结果拼接为一个非常深的特征图,且不同大小卷积核的卷积运算可以得到图像中的不同信息,处理获取到的图像中的不同信息可以得到更好的图像特征
Inception结构通常用于图像分类和识别任务,因为它能够有效地捕捉图像中的细节信息。它的主要优势在于能够以高效的方式处理大量的数据,并且模型的参数量相对较少,这使得它能够在不同的设备上运行。
Inception 模块的设计基于以下两个核心思想:
多尺度特征提取:通过并行的多个卷积分支,Inception 模块能够同时捕捉不同尺度的特征。这使得网络能够更好地处理图像中的多尺度信息,例如小目标和大目标。
1×1 卷积分支:用于提取局部特征,同时减少通道数,起到降维的作用。
3×3 卷积分支:用于捕捉中等尺度的特征。
5×5 卷积分支:用于捕捉较大尺度的特征。
池化分支:通常是一个 3×3 的最大池化或平均池化,用于捕捉更全局的特征。
计算资源优化:通过合理分配计算资源,Inception 模块在不显著增加计算量的情况下,增加了网络的深度和宽度。这使得网络能够在有限的计算资源下达到更高的性能
1x1卷积
1x1卷积核,又称为网中网(Network in Network)。
其实1x1卷积,可以看成一种全连接(full connection)。
辅助分类器
GoogLeNet(Inception v1)是一个22层的深层网络,在2014年提出时面临两个关键挑战:
-
梯度消失:深层网络中反向传播时梯度逐渐衰减
-
训练不稳定:深层参数难以有效更新
解决方案:引入辅助分类器(Auxiliary Classifiers),通过中间监督信号改善训练
辅助分类器主要是为了解决训练深层网络时遇到的梯度消失和过拟合问题 。
辅助分类器的作用
-
缓解梯度消失:由于网络深度达22层,反向传播时梯度可能在前几层衰减严重。辅助分类器通过中间层的额外损失计算,直接向浅层传递梯度信号,加速训练收敛28。
-
正则化效果:辅助分类器引入的额外损失(权重为0.3)对主分类器起到正则化作用,减少过拟合风险。
-
特征融合:中间层的特征具有较强判别能力,辅助分类器通过多尺度特征融合提升模型表达能力。
辅助分类器通常与主要的分类器结合使用,以帮助模型更好地理解图像中的细节和复杂模式。这种技术可以提高模型的泛化能力,使其更准确地预测未知的图像,在GoogLeNet中有两个辅助分类器,分别在Inception4a和Inception4d
尽管GoogLeNet在当时取得了很好的成绩,但它也有一些缺点。
由于其使用了Inception模块,网络的计算复杂度较高。这使得GoogLeNet的训练速度较慢,不太适合对实时性要求较高的应用。
GoogLeNet的网络结构相对复杂,不太容易理解,并且由于辅助分类器的存在,这使得在调试和优化网络时较为困难。
总之,GoogLeNet的计算复杂度高、网络结构复杂是其主要缺点。
ResNet
ResNet的主要特点是采用了残差学习机制。在传统的神经网络中,每一层的输出都是直接通过一个非线性激活函数得到的。但在ResNet中,每一层的输出是通过一个“残差块”得到的,该残差块包含了一个快捷连接(shortcut)和几个卷积层。这样,在训练过程中,每一层只需要学习残差(即输入与输出之间的差异),而不是所有的信息。这有助于防止梯度消失和梯度爆炸的问题,从而使得网络能够训练得更深。
ResNet的主要优点是具有非常深的层数,可以达到1000多层,但仍然能够高效地训练。这是通过使用残差连接来实现的,这种连接允许模型学习跨越多个层的残差,而不是直接学习每一层的输出。这使得ResNet能够更快地收敛,并且能够更好地泛化到新的数据集,ResNet论文中共提出了五种结构,分别是ResNet-18,ResNet-34,ResNet-50,ResNet-101,ResNet-152。
创新
- Residual结构
- Batch Normalization
Residual结构
Residual结构是残差结构,在文章中给了两种不同的残差结构,在ResNet-18和ResNet-34中,用的如下图中左侧图的结构,在ResNet-50、ResNet-101和ResNet-152中,用的是下图中右侧图的结构。
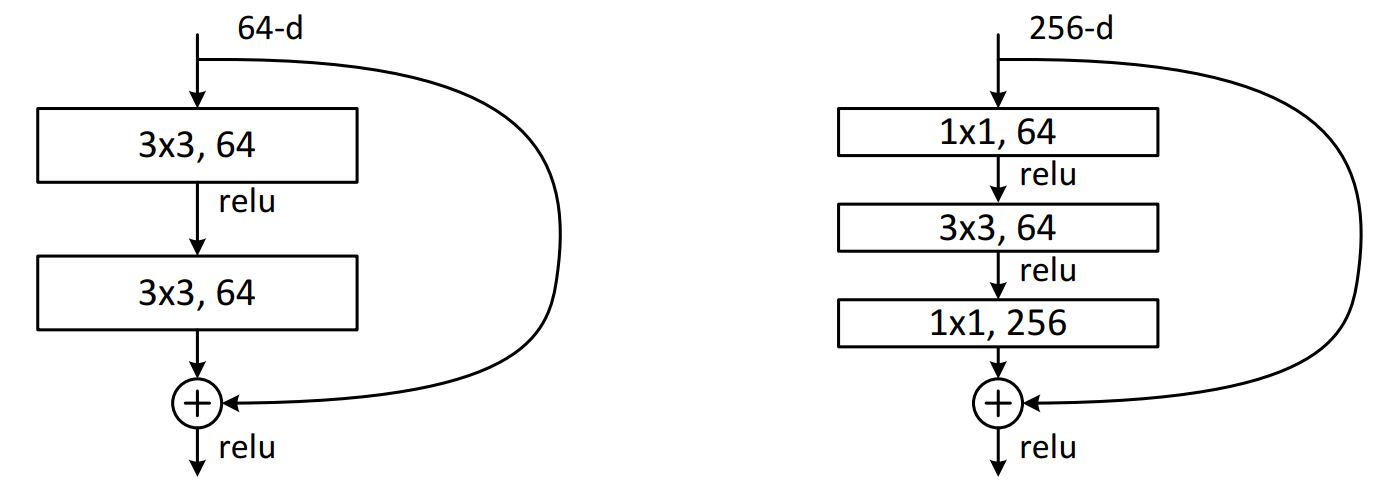
在主分支上有一个圆弧的线从输入特征矩阵直接连到了一个加号,这个圆弧的线是shortcut(捷径分支),它直接将输入特征矩阵加到经过第二次3x3的卷积核卷积之后的输出特征矩阵,注意,这里描述的是加,而不是叠加或者拼接,也就是说是矩阵对应维度位置进行一个加法运算,意味着主分支的输出矩阵和shortcut的输出矩阵的shape必须相同(此时卷积默认padding=1),这里包括宽、高、channels,在相加之后,再经过Relu激活函数进行激活。
为什么**残差结构能够抑制degradation problem(退化)**问题呢?
其实残差的网络结构很简单:,其中,是shortcut的输出特征矩阵,在某些残差结构中它就是输入特征矩阵,是主分支的输出特征矩阵,假如没有残差网络的话直接将输入特征矩阵放入卷积层中进行计算来得到,如果加入残差结构的话,输入特征矩阵进入神经网络得到也就等同于,在与相加得到。
根据,可以求得,可以知道本次残差结构的反向传播不仅与主分支有关,还与有关,当经过主分支的卷积层的导数很小的情况下,那么会对网络起不到更新的作用,但是由于加入了输入矩阵的导数,也就保证了网络导数会一直存在,而不会出现导数消失的情况。
ResNet网络中的残差结构的堆叠有点这类似于这个过程:刚开始的前几个残差结构提取了很重要的一些特征,后几个残差结构负责把一些特征进行细化,当然,后几个残差结构可能有的会学不到东西,但是并不会影响前面的梯度从而造成degradation problem退化问题。
Batch Normalization
Batch Normalization的作用是将一个批次(Batch)的特征矩阵的每一个channels(通道)计算为均值为0,方差为1的分布规律。
一般而言,在一个神经网络输入图像之前,会将图像进行预处理,这个预处理可能是标准化处理等手段,由于输入数据满足某一分布规律,所以会加速网络的收敛。这样在输入第一次卷积的时候满足某一分布规律,但是在输入第二次卷积时,就不一定满足某一分布规律了,再往后的卷积的输入就更不满足了,那么就需要一个中间商,让上一层的输出经过它之后能够某一分布规律,Batch Normalization就是这个中间商,它可以让输入的特征矩阵的每一个channels满足均值为0,方差为1的分布规律。
用Batch Normalization要注意的问题:
Batch Size要设置的大一些,Batch Size越大,均值和方差越接近整个数据集的均值和方差,所以这对GPU显存比较小的机器不是很友好,个人建议要≥4。
ResNet文章中提到BN层要放在卷积和激活之间,并且卷积层不要有偏置,因为有没有偏置都计算出来的结果都是一致的:
没有偏置的公式为:,先放在这里,待会直接做对比。
有偏置的公式为:,其中;
对于均值而言:;
对于方差而言:,
那么可以计算出:。
可以看出来,这个值和没有偏置的时候的是完全一致的。
由于ResNet的结构非常复杂,所以它的训练时间比较长。此外,由于它具有非常深的层数,因此它需要大量的数据来进行训练。
MobileNet
V1
创新
- Depthwise Convolution
- \alpha、\beta 的引入
Depthwise Convolution
DW卷积(Depthwise Convolution),它能够大大减少模型的参数以及运算量。
经典的卷积
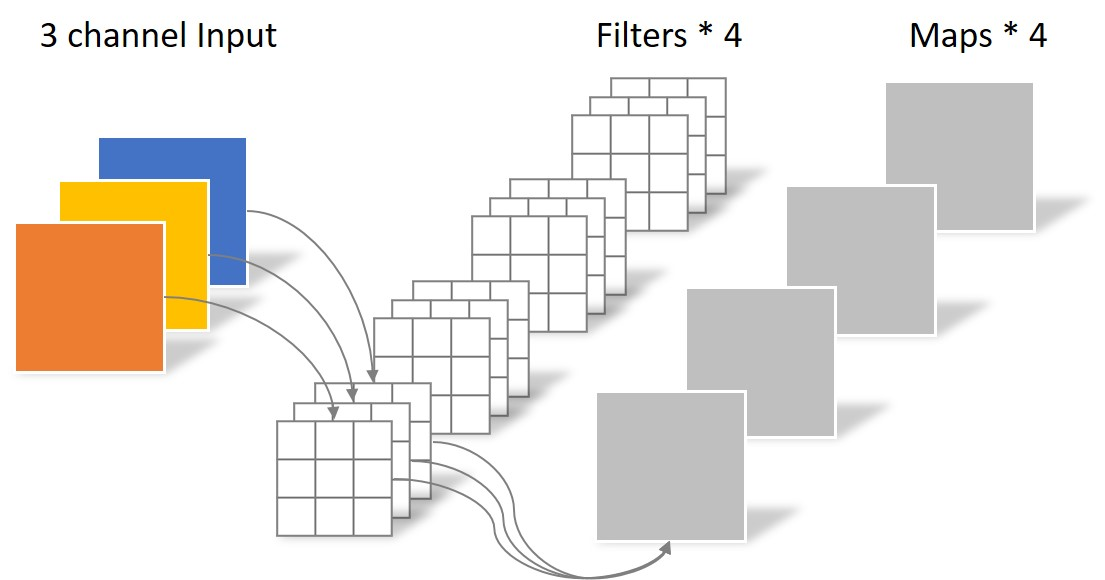
DW卷积
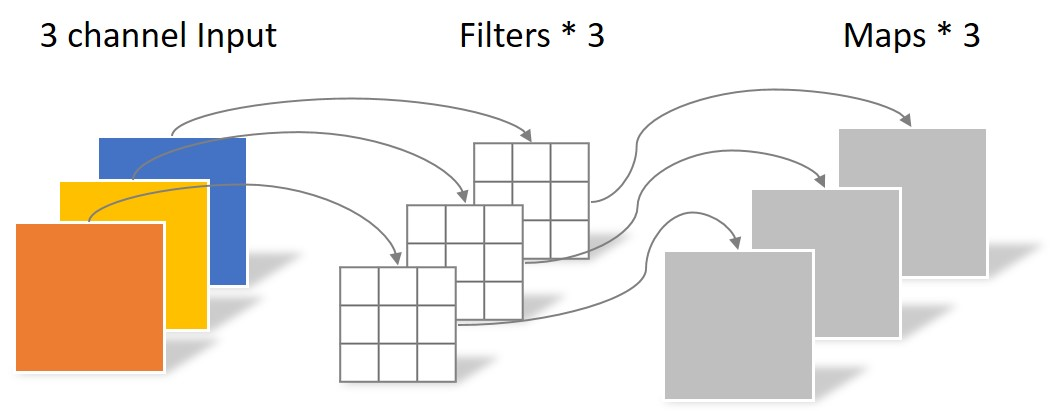
DW卷积的每一个卷积核负责一个输入特征矩阵的channel,那么总结下来:输入特征矩阵的channel = 卷积核个数 = 输出特征矩阵的channel。
深度可分卷积操作(Depthwise Separable Conv
深度可分离卷积 | 李猪兰
这种卷积操作是有两种卷积组成的,即DW卷积和PW卷积(Pointwise Conv)组成,先DW卷积,结果作为PW卷积的输入
PW卷积
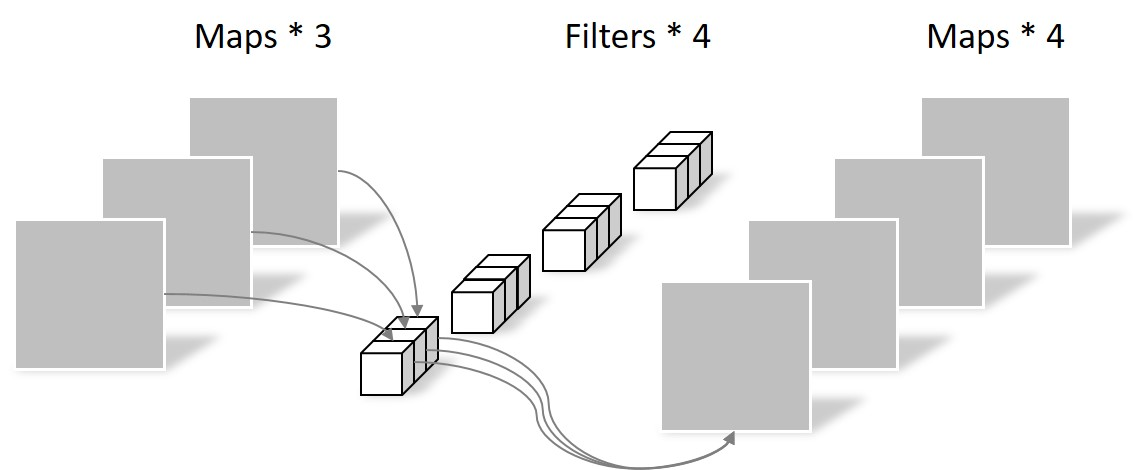
通常情况下,DW卷积核PW卷积是放在一起使用的,这种卷积比普通的卷积能节省大量的计算量,由上图普通卷积、DW卷积、PW卷积三个图可知,普通卷积的输入是3通道,输出是4通道,深度可分卷积由DW和PW一起构成(先DW后PW),所以输入是3通道,输出是4通道。
在使用过程中,发现了部分DW卷积核会废掉的情况,即卷积核的参数为0,为什么会出现这种问题呢?主要是以下几个原因:
卷积核、通道数量以及权重数量太少,感受野太单薄;
Relu激活函数;
精度低时,例如float18,int8这种低精度浮点数表示时很有限。
这种情况会造成特征拿不全的问题,但是这个问题在MobileNetV2中得以改善。
\alpha、\beta
是卷积核个数的倍率,用来控制卷积过程中卷积核的个数,当取不同的的时候,准确率、计算量和参数量是不一样的
是分辨率参数,即输入图像尺寸的参数
这种情况会造成特征拿不全的问题,但是这个问题在MobileNetV2中得以改善。
V2
创新
- Inverted Residuals(倒残差结构)
- Relu6
- Linear Bottlenecks
- Shortcut
- 拓展因子
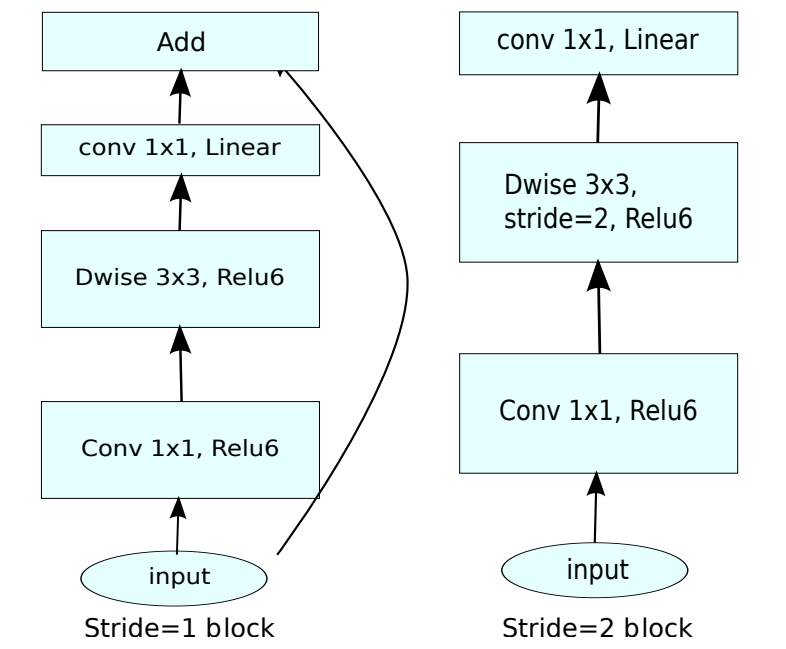
Inverted Residuals(倒残差结构)
在之前的ResNet残差结构是先用1x1的卷积降维,再升维的操作。而在MobileNetV2中,是先升维,再降维的操作,所以该结构叫倒残差结构,网络结构表格中的bottleneck就是倒残差结构。
残差结构的过程是:
1x1卷积降维
3x3卷积
1x1卷积升维
即对输入特征矩阵进行利用1x1卷积进行降维,减少输入特征矩阵的channel,然后通过3x3的卷积核进行处理提取特征,最后通过1x1的卷积核进行升维,那么它的结构就是两边深,中间浅的结构
倒残差结构的过程是:
首先会通过一个1x1卷积层来进行升维处理,在卷积后会跟有BN和Relu6激活函数
紧接着是一个3x3大小DW卷积,卷积后面依旧会跟有BN和Relu6激活函数
最后一个卷积层是1x1卷积,起到降维作用,注意卷积后只跟了BN结构,并没有使用Relu6激活函数。
结构应该是中间深,两边浅
Relu6
Relu6激活函数是Relu的变种,它的输入小于0时,结果为0,输入大于6时:结果为6。在0到6之间时:。
如果对Relu的激活范围不加限制,输出范围为0到正无穷,如果激活值非常大,分布在一个很大的范围内,则低精度的float16无法很好地精确描述如此大范围的数值,带来精度损失,所以在量化过程中,Relu6能够有更好的量化表现和更小的精度下降。
Linear Bottlenecks
Linear Bottlenecks(线性瓶颈)
Shortcut
Shortcut并不是该网络提出的,而是残差结构提出的。
shortcut将输入与输出直接进行相加,可以使得网络在较深的时候依旧可以进行训练。
V3
创新
- 更新Block
- 使用NAS搜索参数
- 重新设计耗时层
NAS是Neural Architecture Search,实现网络结构搜索
https://zhuanlan.zhihu.com/p/450940875。
在使用过程中,可能会出现MobileNetV3准确率不如MobileNetV2的情况,MobileNetV3是来自于Google的,自然它更关注的是网络在Android设备上的表现,事实也的确如此,作者主要针对Google
Pixel硬件对网络做了参数优化。当然这并不意味着MobileNet V3就是慢的了,只不过它无法在其他一些设备上达到最佳效果。
V4
创新
- Universal Inverted Bottleneck(UIB)——统一可搜索的构建块
- Mobile MQA——为移动加速器定制的注意力机制
- 两阶段NAS配方——硬件感知的结构搜索
- 蒸馏增强训练——精度再提升
DenseNet
密集连接,特征复用强,参数效率高
SENet(Squeeze-and-Excitation)
引入 通道注意力机制,可嵌入其他网络提升性能
ResNeXt
ResNet 的升级版,引入 分组卷积,性能更强
ShuffleNet V1/V2
轻量级网络,通道打乱机制,适合移动端
EfficientNet
复合缩放策略,精度高、参数少,EfficientDet 的 backbone
RegNet
Facebook 提出,系统设计网络结构,Detectron2 默认使用
Vision Transformer (ViT)
使用 Transformer 架构,无卷积,在大规模数据上表现强劲
Swin Transformer
分层 Transformer,兼容 CNN 结构,在检测/分割任务中表现优异
怎么选择
按类型分类
| 类型 | 代表模型 |
|---|---|
| 标准 CNN | AlexNet, VGG, GoogLeNet, ResNet, DenseNet, ResNeXt |
| 轻量级 | MobileNet V1/V2/V3, ShuffleNet V1/V2, EfficientNet |
| 注意力机制 | SENet, CBAM(可嵌入其他网络) |
| Transformer 系列 | ViT, Swin Transformer, DeiT |
按用途分类
目标检测
| 任务场景 | 推荐 backbone | 理由 | 常用组合 |
|---|---|---|---|
| 高精度 服务器/GPU |
ResNet-50-FPN ResNet-101-FPN |
鲁棒、预训练多、FPN 天生适配 | Faster R-CNN、Mask R-CNN、RetinaNet |
| 轻量级 移动端 |
MobileNet-V3-Large-FPN | 参数量 ↓90%,仍保留 FPN 结构 | SSD-Lite、YOLOv4-tiny、EfficientDet-D0 |
| 超高精度 比赛/科研 |
Swin-Tiny-FPN RegNetY-4GF-FPN |
分层 Transformer / 设计空间搜索 | Detectron2、MMDetection 一键调用 |
语义分割 / 实例分割
| 任务场景 | 推荐 backbone | 理由 | 常用组合 |
|---|---|---|---|
| 通用 | ResNet-50-DeepLabV3+ ResNet-101-DeepLabV3+ |
空洞卷积 + ASPP,成熟 pipeline | DeepLabV3+、U-Net++ |
| 实时 | MobileNet-V2 ShuffleNet-V2 |
速度 30+ FPS@720p, TensorRT 友好 | BiSeNet、SwiftNet |
| 高精度 | Swin-Tiny-UperNet RegNetY-8GF-MaskFormer |
全局上下文强,MaskFormer 统一分割 | MMSeg、Detectron2 |
微调
| 数据量 | 推荐 backbone | 技巧 |
|---|---|---|
| 千级 | VGG-16 / DenseNet-121 | 冻结前 1/3 层 + 小学习率 1e-4 |
| 万级 | ResNet-50 / EfficientNet-B0 | 全局微调 + RandAugment |
| 百级 | Swin-Tiny | 冻结 patch embedding,只训 stages 3-4 |
总结
-
服务器精度 → ResNet-FPN 永远是 baseline;
-
移动端速度 → MobileNet-V3 先跑通,再试 ShuffleNet-V2;
-
Transformer 尝鲜 → Swin-Tiny 最小可用,RegNet 调参最省心;
-
边缘量化 → 选 无 SE 模块 的版本(SE 对 INT8 不友好)。
(来自ai)