GAN
编码器
自编码器AE
把输入压成“短码”再还原,像“压缩-解压”软件,只是压缩表是神经网络自己学的。
核心结构
编码器 f(x)→z(短向量)
解码器 g(z)→x̂(还原图)
训练目标
最小化“原图 vs 还原图”的像素误差,让 x̂ 尽量像 x;潜码 z 无任何额外约束。
典型用途
-
降维可视化(比 PCA 非线性更强)
-
图像/语音去噪(训练时加噪声,学会“干净→干净”)
-
特征预训练(把 f(x) 抽出来喂给下游分类器)
-
异常检测(正常样本重构误差低,异常高)
变分自编码器VAE
AE 的“概率版”:不再压成“一个点”,而是压成“一团高斯云”,因此既能解压还原,也能随机造新图。
核心结构
编码器输出两个向量:μ 和 σ → 用“重参数化”技巧采样 z
解码器把 z 变成 x̂
训练目标
同时优化两项:
-
还原图要真(似然项)
-
高斯云必须接近标准正态(KL 散度项)
→ 保证潜空间连续、可采样,还能算生成概率。
典型用途
-
生成新样本(人脸、手写数字、分子结构)
-
潜空间平滑插值(两张脸渐变)
-
可控生成(把标签一起喂进去,叫 CVAE)
-
表示解耦(β-VAE 让潜码各维度对应独立语义,如“角度/光照”)
第一次接触GAN
DCGAN,全称是 Deep Convolution Generative Adversarial Networks(深度卷积生成对抗网络)

1 | # 想象一个造假币的故事: |
条件生成GAN
有监督
CGAN(Conditional GAN)
-
怎么做
最早的条件版:把 one-hot 标签 y 分别拼到噪声 z(G 输入)和图像 x(D 输入),变成向量[z;y]和[x;y],再正常对抗训练。 -
为什么有用
标签当额外信息,D 同时判断“真/假”+“是否匹配条件”,迫使 G 学到“给定 y 就应生成对应模态”的映射。 -
局限
条件 y 必须成对出现;如果标签噪声大或类别多,训练不稳定。 -
论文
Mirza M, Osindero S. Conditional Generative Adversarial Nets. arXiv 2014. https://arxiv.org/abs/1411.1784
AlignGAN(跨域配对生成)
-
场景
源域有标签,目标域无标签或标签空间不同,希望“把源域图片+标签”翻译成“目标域同语义的图片”。 -
怎么做
三套网络:-
共享潜码 E:把两域图片压到同一个 z;
-
域专属 G:根据 z+标签 y 生成目标域图像;
-
语义一致性 D:判断“生成图与条件 y 是否语义对齐”。
额外加 cycle-consistency 和潜码对齐损失,保证翻译前后标签不变。
-
-
优点
不需要像素级配对,只需源域标签即可实现“语义对齐跨域生成”。 -
论文
Zhou S, et al. AlignGAN: Learning to Align Cross-Domain Images with Conditional Generative Adversarial Networks. AAAI 2020. https://arxiv.org/abs/1907.01452
无监督
InfoGAN(信息最大化 GAN)
-
目标
没有标签,也能让潜码的某些维度“自动”对应可解释因子(旋转角、粗细、光照)。 -
怎么做
把噪声拆成两部分:-
z:不可压缩噪声;
-
c(小维度):希望与生成图互信息最大。
额外训练一个“辅助网络 Q”去预测 c,最大化 Q 的预测似然 ≈ 最大化 I(c;G(z,c))。
-
-
效果
无需任何标签,c 的每一维自动抓住高维变化模式。 -
缺点
互信息估计用蒙特卡洛,训练慢;c 维度需人工选。 -
论文
Chen X, et al. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. NeurIPS 2016. https://arxiv.org/abs/1606.03657
半监督
ACGAN(Auxiliary Classifier GAN)
-
场景
只有一小部分图像有标签,想同时做:-
高保真生成;
-
用少量标签把类别信息塞进生成器;
-
顺便训练一个分类器。
-
-
怎么做
D 改成双头:-
真/假头:传统对抗 loss;
-
分类头:交叉熵 loss(对真实图用真标签,对生成图用 G 输入的 y)。
G 输入噪声+标签 y,目标骗过 D 的“真/假”头,同时让 D 分类头也相信自己是对应类别。
-
-
结果
在 CIFAR-10 上只用 4 k 标签即可达到 85% 分类准确率,同时生成 128×128 高质量样本。 -
论文
Odena A, et al. Conditional Image Synthesis with Auxiliary Classifier GANs. ICML 2017. https://arxiv.org/abs/1610.09585
多尺度生成GAN
核心思想:一次生成全分辨率太难 → 先低分辨率“搭骨架”,再逐级补细节,减轻 G/D 训练压力。
金字塔图像生成GAN(Laplacian GAN)
LAPGAN:基于残差的学习机制,多尺度增加生成分辨率
-
怎么做
-
把图像做拉普拉斯金字塔分解:每个级别只存“残差”高频;
-
每层配一个独立 CGAN:输入“上一级的上采样图+噪声+标签”,生成当前级残差;
-
最后把残差逐级加回去,得到 256×256 图像。
-
-
优点
每级仅学“残差”,分布更简单,训练稳定;2015 年即生成 256×256 逼真鸟类、人脸。 -
缺点
级联 3–4 个独立 G/D,参数量大,推理串行慢。 -
论文
Denton E, et al. Deep Generative Image Models using a Laplacian Pyramid of Adversarial Networks. NeurIPS 2015. https://arxiv.org/abs/1506.05751
渐进式图像生成GAN
Progressive GAN:基于残差与多尺度的学习机制,但只有一个G和一个D
-
怎么做
只用 一个 G、一个 D,但训练过程像“盖楼”:-
从 4×4 开始,G 生成 4×4 真/假图,D 判别;
-
训练稳定后,平滑“淡入”8×8 层(新旧层用 α 混合),继续对抗;
-
重复直至 1024×1024。
每级新增层都用 残差式 skip 学习,只需补“高频细节”,难度低。
-
-
优点
单 G/D 结构简单,推理快;首次实现 1024×1024 人脸高清生成,FID 8.0(当时最佳)。 -
缺点
训练周期长(Tesla V100 上 2 周);对超参敏感,需 careful γ 调节。 -
论文
Karras T, et al. Progressive Growing of GANs for Improved Quality, Stability, and Variation. ICLR 2018. https://arxiv.org/abs/1710.10196
| 类别 | 代表 | 是否多级网络 | 是否残差 | 主要贡献 |
|---|---|---|---|---|
| 条件-有监督 | CGAN | 否 | 否 | 最早把标签塞进 GAN |
| 条件-跨域 | AlignGAN | 否 | 部分 | 无配对也能语义对齐 |
| 条件-无监督 | InfoGAN | 否 | 否 | 潜码自动解耦 |
| 条件-半监督 | ACGAN | 否 | 否 | 用少量标签同时生成+分类 |
| 多尺度-金字塔 | LAPGAN | 是(3–4 级) | 是(残差=高频) | 逐级残差补细节 |
| 多尺度-渐进 | ProGAN | 是(1 G/D,逐级放大) | 是(平滑 fade-in) | 单模型 1 k² 高清生成 |
GAN的评估
通过数据集的划分进行评估
GAN-base根据真实图像训练了分类器,并在真实图像上进行测试。
GAN-train根据GAN生成图像训练了一个分类器,并在真实图像上进行测试,该指标与GAN-base比较,可评估GAN生成图像的多样性和真实性。
GAN-test根据真实图像训练了分类器,并在GAN生成图像上进行评估,该指标与GAN-base比较,可评估GAN生成图像的真实性(生成图像与数据流形之间的接近程度)。
Inception分数
使用熵对样本的质量进行评估
样本的质量问题,对质量高的生成图像x,分类模型可将其以很高的概率分类成某个类,即标签向量p(yx)数值比较集中,当p(y|x)为one-hot分布时,熵达到最小值0。
使用熵对样本的多样性进行评估
样本的多样性问题:若样本{x1,x.,…,x}多样性比较好,则标签向量(y,y,…,y)}的类别分布也应该是比较均匀的
IS只考虑生成器的分布,而忽略数据集的分布,无法检测生成器过拟合问题,可能会鼓励模型只学习清晰和多样化图像
M-IS(Modifified Inception Score):关注了类内模式崩溃的问题
1-最近邻分类器
通过判定真实数据分布 pdata 和生成数据分布 pg 是否相等
Fréchet Inception Distance
计算生成样本和真实样本的 CNN 特征构成的两个高斯分布的弗雷歇距离
Kernel MMD(Kernel Maximum Mean Discrepancy)
核最大均值差异,选择一个核函数k(x,y),计算样本距离
Wasserstein Distance
使用一个已经训练好的判别器D(x)对真实样本输出高预测值,假样本输出低预测值
StyleGAN
V1
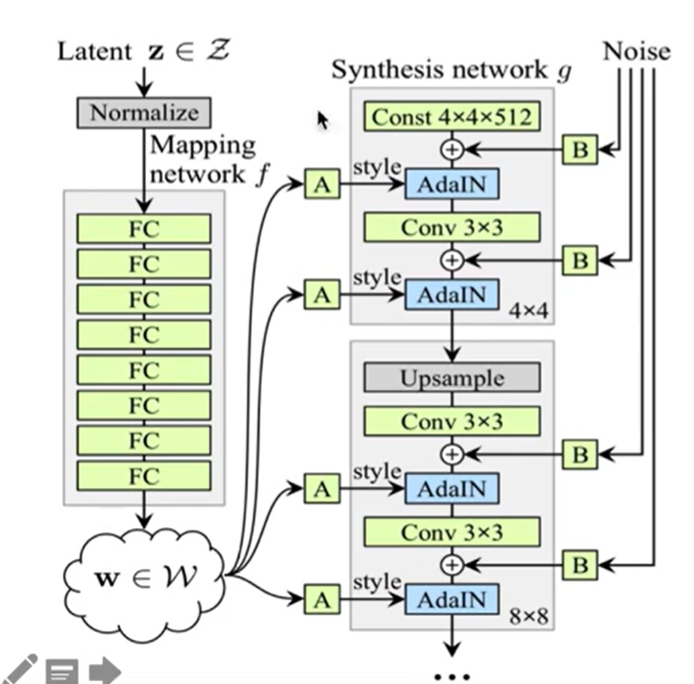
由Mapping network f和Synthesis network g两部分组成
Mapping network f:摆脱输入向量z受输入数据集分布的影响,更好的实现属性解耦合。
Synthesis network g:512维的向量w,经过仿射变换A,得到风格向量s。AdaIN层实现分层的风格控制
风格分层,分辨率越大就是越宏观的特征
B表示可学习的权重系数
加噪声增加生成图像的多样性,越复杂精细的地方受噪声影响就越明显
训练技巧
mixing regularization(样式混合):随机交换两个 w 向量的部分内容,进行拼接,阻止相邻特征耦合
Truncation Trick(截断):解决低密度区域的生成质量问题
评估
路径长度perceptual path length:什么是好的Latent向量看生产期是否选择了最近的路线,perceptual path length是Latent 空间中端点的平均距离,训练过程中相邻时间节点上的两个生成图像的距离。
线性可分性Linear separability:
- 使用分布 z ~ P (z) 生成 200,000 张图片,训练 1 个 CNN 图片分类器得到某一个属性的二分类标签
- 对 Latent 向量 Z 或者 W 使用 SVM 进行分类,计算条件熵 H (Y|X),X 是 SVM 分类器结果,Y 是 CNN 图片分类器结果
H(Y|X)意义:需要多少额外信息来决定真的类别,更低的值反映出更一致Latent space方向
V2
V1的缺陷
StyleGAN 生成器中液滴伪影:Instance normalization 标准化层带来的瑕疵
V2结构
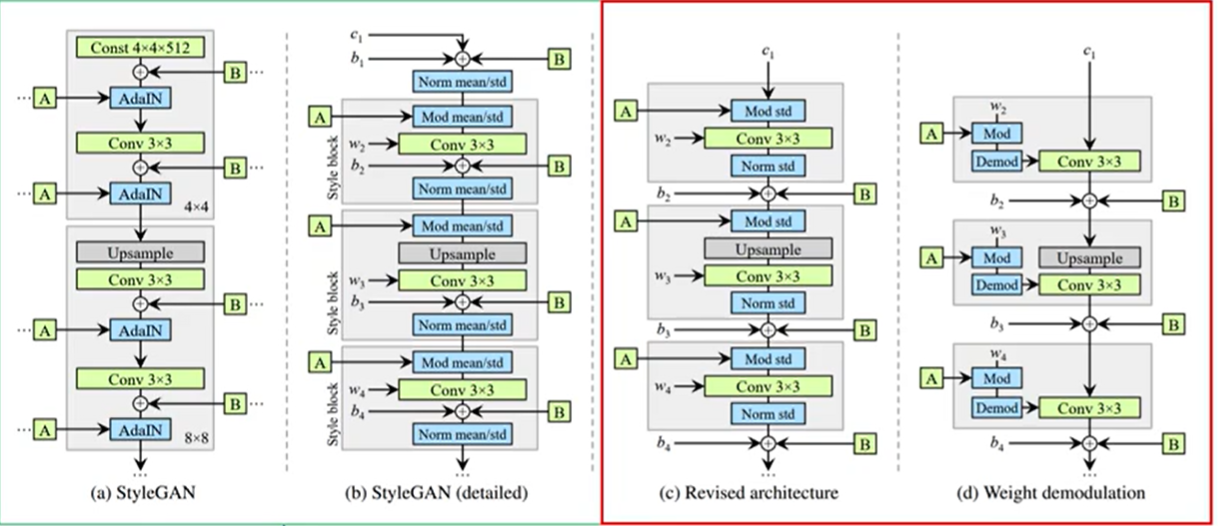
- Norm 中去除 mean,将 noise 和 bias 移到 style block 外。
- 简化了噪声广播操作(对所有特征图 使用单一共享比例因子)
- 权重归一化:将 IN 替换为 demodulation 层,基于信号的统计假设,而不是特征图的实际内容 (相对较弱的调制)
Mod 层:通过缩放卷积权重来替换缩放卷积的每个输入特征图
demodulation层:通过缩放相应权重的L2范数来缩放输出
训练技巧
残差学习:去掉渐进式分辨率提升训练策略(Progressive growing),使用残差结构。
路径长度正则化:假设如果在潜在空间中的每个点处,小的位移都在图像空间中产生相同大小的变化,而与方向无关,则认为从潜在空间到图像空间的生成器映射条件良好,latent vector 向量更加线性与平滑
数据增强与仿真GAN
BAGAN (balancing generative adversarial network),解决类别不平衡(class inbalance)
SimGAN,提高仿真数据的真实性
视频生成与预测GAN
VideoGAN,视频生成
MDGAN,视频预测
FAQ
GAN和扩散模型
-
生成质量(FID / IS / 保真度) • GAN:在 2021 年以前,BigGAN、StyleGAN 系列在 ImageNet 1024² 上保持 FID 3~5 的纪录。
• 扩散模型:Dhariwal & Nichol 通过改进 U-Net 与分类器引导,将 ImageNet 256² FID 降到 2.97,首次在公开数据集上系统性击败同期最佳 GAN。
论文:Dhariwal P, Nichol A. Diffusion Models Beat GANs on Image Synthesis. NeurIPS 2021. https://arxiv.org/abs/2105.05233 -
训练稳定性(模式崩溃与收敛性) • GAN:理论上存在两玩家博弈的不稳定解,实践中易出现模式崩溃。Borji 综述中系统归纳了 18 种 GAN 训练失败模式。
• 扩散模型:最大似然或变分下界目标函数无对抗项,Ho et al. 证明 DDPM 在 CIFAR-10 上训练 1000 个 epoch 仍保持稳定收敛。
论文:Ho J, et al. Denoising Diffusion Probabilistic Models. NeurIPS 2020. https://arxiv.org/abs/2006.11239 -
推理速度与计算成本 • GAN:一次前向即可生成样本,单张 256² 图像在 RTX-3090 上约 3 ms(GigaGAN 实测)。
• 扩散模型:标准 DDPM 需 1000 步去噪,耗时数十秒;即便 DDIM 加速 50 步仍比 GAN 慢 1~2 个数量级。
论文:Song J, et al. Denoising Diffusion Implicit Models. ICLR 2021. https://arxiv.org/abs/2010.02502 -
样本多样性 • GAN:当判别器过强时容易丢失低概率模式,导致多样性下降(Mode Drop)。
• 扩散模型:基于对数似然训练天然鼓励覆盖所有模式,Kingma et al. 证明扩散模型在 ImageNet 上的召回率(Recall)显著高于 StyleGAN2。
论文:Kingma D, et al. Variational Diffusion Models. NeurIPS 2021. https://arxiv.org/abs/2107.00630 -
可控 / 条件生成 • GAN:条件 GAN 早期依赖类别标签或投影判别器;StyleGAN 通过潜空间编辑实现局部语义控制,但缺乏文本细粒度引导。
• 扩散模型:Classifier-Free Guidance 与大规模文本编码器(CLIP、T5)结合,Stable Diffusion、DALL-E 2 支持基于提示词的高精度可控生成。
论文:Ramesh A, et al. Hierarchical Text-Conditional Image Generation with CLIP Latents. arXiv 2022. https://arxiv.org/abs/2204.06125 -
训练数据效率 • GAN:需大量样本才能稳定训练;StyleGAN3 在 70 k ImageNet 类别子集上仍需要精细超参调整。
• 扩散模型:DDPM 在 CIFAR-10(50 k)与 CelebA-HQ(30 k)即可训练出高质量模型,表现出更好的小数据鲁棒性。
论文:Ho J, et al. Denoising Diffusion Probabilistic Models. NeurIPS 2020(实验部分数据消融表). -
可解释性与潜在空间 • GAN:z 空间语义高度纠缠,需额外潜码解耦技术(如 SeFa)。
• 扩散模型:逐层去噪可视化为“雕刻”过程,直观可解释;同时支持在任意 t-step 注入控制信号,实现中间层干预。
论文:Meng C, et al. SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations. ICLR 2022. https://arxiv.org/abs/2108.01073 -
模型压缩与实时化 • GAN:天然单步生成,无需额外压缩即可部署。
• 扩散模型:最新一步蒸馏(One-Step Distillation)结合对抗损失,可在保持 FID < 5 的前提下实现 1-step 生成,速度接近 GAN,但需额外蒸馏训练。
论文:Sauer A, et al. Adversarial Score Distillation: Rapidly Surpassing the Teacher in One Step. arXiv 2024. https://arxiv.org/abs/2410.14919 -
理论可扩展性与连续时间框架 • 扩散模型可通过随机微分方程(SDE)/概率流 ODE 统一连续时间框架,具备更丰富的理论工具(Wasserstein 收敛、分数匹配误差界等)。
论文:Song Y, et al. Score-Based Generative Modeling through Stochastic Differential Equations. ICLR 2021. https://arxiv.org/abs/2011.13456
| 维度 | GAN | 扩散模型 | 关键论文 |
|---|---|---|---|
| 生成质量 | 高(≤2021 SOTA) | 更高(2022 起普遍领先) | [Dhariwal 2021] |
| 训练稳定性 | 易模式崩溃 | 稳定收敛 | [Ho 2020] |
| 推理速度 | 单步,毫秒级 | 50~1000 步,秒级 | [Song 2021] |
| 多样性 | 受限于判别器过拟合 | 高(似然训练覆盖长尾) | [Kingma 2021] |
| 条件可控性 | 弱(无文本引导) | 强(Prompt、ControlNet) | [Ramesh 2022] |
| 小数据训练 | 困难 | 相对鲁棒 | [Ho 2020] |
| 可解释性 | 低(潜空间纠缠) | 高(逐层去噪可视化) | [Meng 2022] |
| 实时部署 | 原生支持 | 需蒸馏/量化 | [Sauer 2024] |